Claw has been keeping me occupied at all times in the day and especially over the weekends. The internet (or could just be my echo chamber) is getting wilder with the experiments. I have tried my hand at a few over the past few weeks. And this is a post about one such experiment that happened this weekend.
The Idea
The idea is a simple one, can I augment LLM knowledge with data from a curated set of sources that can unlock cross domain connections. Think of it like RAG but the lookup happens in the background, after the model has already responded.
The obvious inspiration for this was Kahneman’s Thinking, Fast and Slow. For the uninitiated, the high level idea is System 1 is fast and automatic ⚡. You see 2 + 2 and the answer is just there. System 2 is slow and deliberate 🐢. Long division. Tax returns. Actually reading a dense paper instead of skimming the abstract.
This is not a new idea and in fact LLMs already kinda do this. The idea of two Systems was the genesis behind the thinking models like o3, Deepseek etc. Like captured in detail here “From System 1 to System 2”, which traces how modern AI is moving from reactive inference toward deliberate, multi-step reasoning. Chain-of-thought prompting, thinking modes, reflection loops. All interesting attempts to bolt a System 2 onto what is fundamentally a System 1 architecture.
But in an interactive Claw-like system, additional responses from the agent are acceptable as long as they add signal. So what if we nudge the model into something it genuinely never considered, if (and it’s a big if) you had the data to unlock such connections.
The Corpus
Every system like this lives or dies by its data. I needed something broad, curated, and structured. Spanning many domains, not just one vertical. And luckily I had one such place that curated one of my favorite podcasts, BBC Radio 4’s In Our Time by Melvyn Bragg and now run by Misha Glenny, Braggoscope. Philosophy one week, quantum mechanics the next, then the fall of Carthage. 1,088 episodes spanning two decades. Just 🤌.
What makes it special isn’t the content though, it’s the metadata. Each episode comes with academic guests, curated reading lists, Dewey Decimal classification, and (this is the important part) editorially cross-referenced related episodes. “Stoicism” relates to “Epicureanism” and “Cynicism,” but also to “Daoism” and “Chinese Legalism.”
So I shamelessly did what everyone does when they find good data: I scraped all 1,088 episodes and built a knowledge base from it. 🕷️
How It Works
The whole thing is a 4-layer system. The critical design rule up front: System 1 responds first. The KB check happens after. If the agent reads the KB before responding, it anchors on whatever it finds. The LLM’s own knowledge, which is often better, gets contaminated. System 2 only adds value when it runs independently.
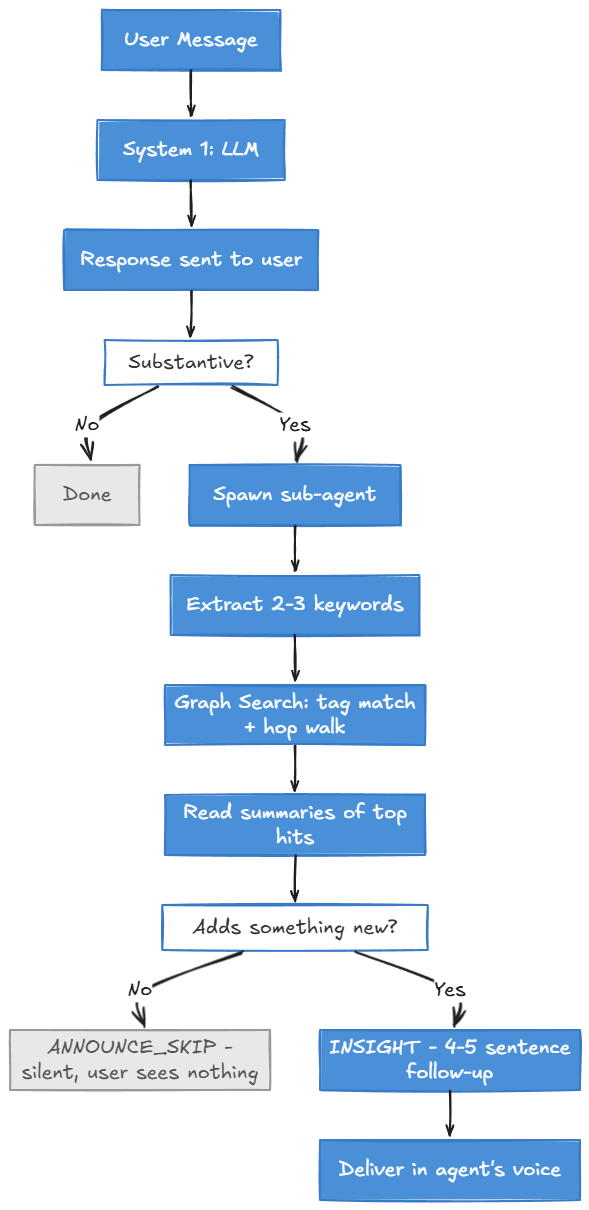
System 1 responds first. System 2 fires in the background, checks the knowledge graph, and only speaks up if it finds something the LLM missed.
The Graph
All 1,088 topics become nodes. Edges come from the editorial cross-references (weight 1.0, curated human connections), content cross-references where one topic mentions another (weight 0.5, noisier, incidental), and shared academic guests across episodes (weight 0.7).
1,093 nodes. 8,491 edges. Average of 15.5 connections per node. No embeddings, no vector database, no NLP pipeline. Tags are just cleaned text tokens from titles and descriptions. For this system, the value turned out to be in the edges, the connections, not in the node representation.
To give you an idea of what the graph looks like here are few nodes centered around Stoicism. Stoicism, 23 edges. The 1-hop neighborhood is what you’d expect. Epicureanism, Cynicism, Daoism. Obvious. The LLM already knows those are related. But follow the graph one more hop and you land on Comedy in Ancient Greek Theatre, The Han Synthesis, the Pelagian Controversy. Those are the interesting ones. Those are the connections a bare LLM won’t make on its own.
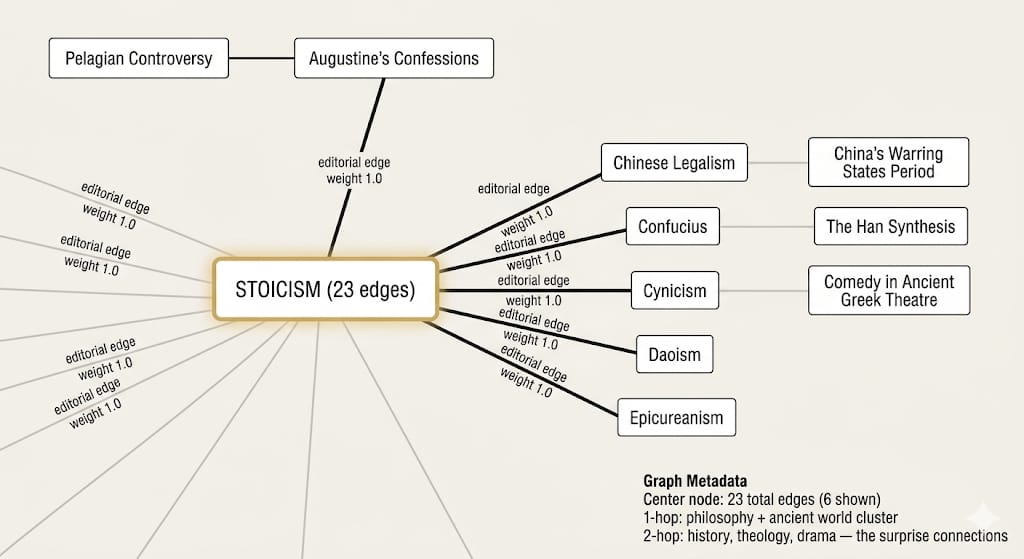
Stoicism node with 23 edges. 1-hop neighbors are the obvious connections. 2-hop neighbors are where the surprises live.
The Lookup
When the sub-agent fires, it runs a graph search. Tag match against the conversation keywords to find seed nodes, walk 1 hop out along edges (scoring neighbors by seed score × edge weight × decay), and conditionally walk a second hop if the first didn’t surface enough strong hits. Rank, return the top 3-5 candidates.
The key here is that graph traversal surfaces what’s connected through human judgment, not just what’s semantically nearby. A human editor decided Stoicism connects to Chinese Legalism. Two hops out, you reach Comedy in Ancient Greek Theatre, a connection that makes sense once you see it but that you wouldn’t stumble into by keyword search alone. The trade-off is real. “Fusion energy” won’t find “nuclear power” unless the words literally appear. But for this kind of associative recall, graph structure seemed like the better fit.
The Judge
The temptation with any system like this is to surface everything you find. This system tries to be more selective. It reads the candidate summaries and asks: does this add something the LLM didn’t already say?
Surface it if it’s a historical parallel the agent missed, a surprising cross-domain connection, or a reframe that changes how you’d think about the topic. Discard it if it’s something obviously related, repeats what was already covered, or amounts to “we have an entry on X” without an actual insight.
Most lookups result in nothing worth saying. That’s the point. The system is designed for a ~70% discard rate. Rare, genuine “huh, I didn’t think of that” moments are worth more than frequent catalog references.
Delivery
When there’s something worth saying, it arrives as a natural follow-up 15-45 seconds after the original response. When there isn’t, a special token (ANNOUNCE_SKIP) suppresses any visible output. The user never sees the misses. Ideally, the feature stays invisible until it has something worth saying.
The Results
Now for the interesting part, the results. I ran this for about 10 different topics and as expected, LLM knowledge (our System 1) usually covered the bases. But there were 2 cases where the System 2 did add to the discussion. The Cold War Art was definitely a good add. The Fusion Energy was also informative but you could argue that a web search would have yielded the same.
Cold War Art
I ask about Art in the Cold War and Picasso’s influence on US artists. System 1 gives a solid response covering the CIA-Abstract Expressionism connection, Picasso’s direct influence on Pollock and de Kooning. Then the sub-agent comes back with something the LLM didn’t touch:


Cold War Art with Sub Agent Response
Fusion Energy
Same pattern. I ask about fusion energy, the agent covers NIF ignition, JET’s final run, ITER. Then the sub-agent fires:
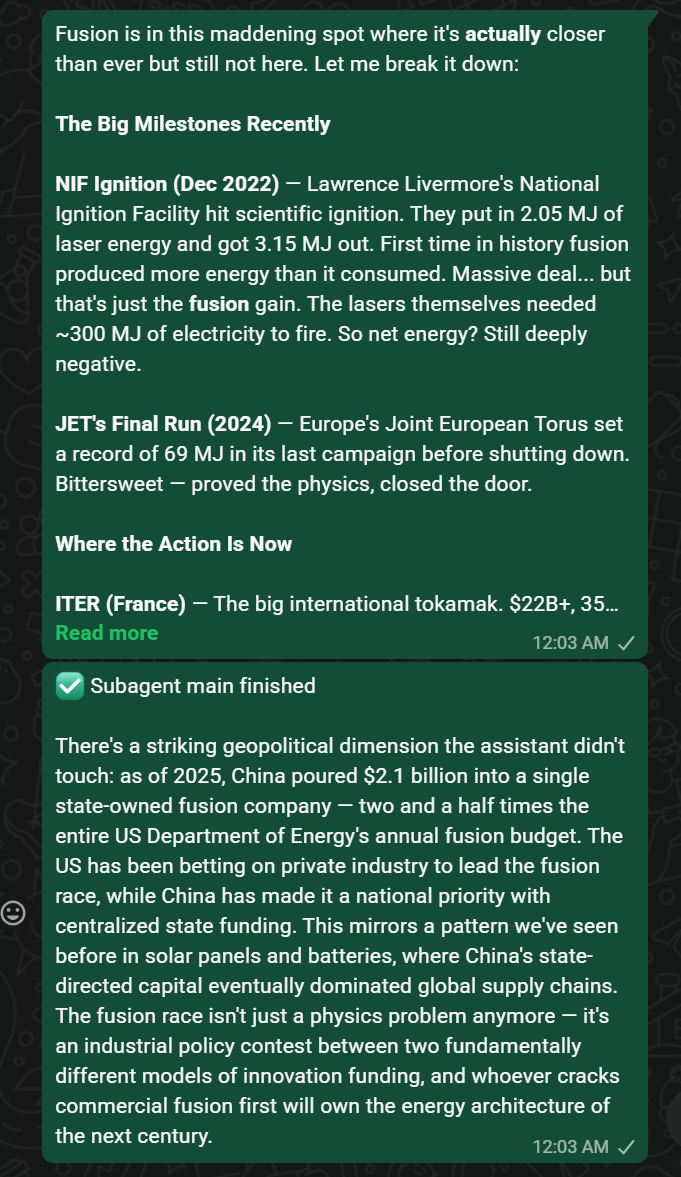
Fusion Energy with Sub Agent Response
What to make of these results?
I think we are onto something because a non-intrusive sub-agent in the background never hurt anyone. The value of this system scales with two things: the breadth of the graph and the topics I happen to discuss with Claw. Right now the corpus is heavily weighted toward history, philosophy, and science because that’s what In Our Time covers.
The plan is to keep growing it. Manual nodes and edges as I find interesting sources, articles worth indexing, maybe even podcast episodes from other shows.
It is an interesting pattern to consider though, one that I’m sure has been explored in various systems or is already available on ClawHub as a skill. If madness is a lot like gravity, all it takes is a little push. Epiphany is a lot like lightning, all it takes is a little spark. 🧠
Right, tea or coffee?